海量的基于Web的FTP搜索引擎系统的设计与实现
TheDesign&RealizationofaPowerfulFTPSearchEngineSystem---陈华2001.
6.
10摘要在因特网上对众多FTP站点进行快速的文件条目查找,是网络信息搜索的重要组成部分.
本文以"天网"FTP搜索引擎为例,介绍了千万级基于WEB的强大的FTP搜索引擎的设计与实现,并重点分析了系统所采用的关键技术和方法.
关键词FTP,搜索引擎,WWWAbstractFTPSearchEngineisapowerfultooltosearchusefulfilesforusersfromvariousresourcefulFTPsites.
Inthispaper,mainlydescribedarethedesignandimplementationofourFTPsearchengine,aswellasthekeytechnologiesandmethodsweadopt.
KeywordFTP,SearchEngine,WorldWideWeb目录引言…4搜索引擎的历史与发展…4搜索引擎的起源…4真正意义的搜索引擎…4Ftp的搜索引擎…5I、基于文本的ftp搜索引擎:Archie.
5II、基于Web的Ftp搜索引擎.
5天网ftp搜索引擎的现状…5天网Ftp搜索产生的起源与发展历史.
5天网ftp搜索引擎的现状…6提供的功能…6文件类型的分类…6时间过滤…6大小过滤…6精确匹配…6站点限制…6结果中查询功能…6支持常用的*,,与,并操作…7多语言版本…7快捷方式系统…7数据量…7站点数量在3000以上…72.
文件条目1300万左右…7快捷方式约一千条…7访问量…7日页面下载量在3万左右…7日访问人数在1.
5万以上…8海量ftp搜索引擎的系统结构设计…9系统的结构设计:四大模块和五个数据库…9数据库功能和结构说明…10文件类型库…10站点列表库…11素材数据库…11索引数据库…12快捷方式数据库…13搜集建库模块…14搜集建库过程说明…14站点获得策略…14并发搜集策略…15分布搜集策略…15多次尝试和断点续搜…15线性的建库过程…15数据库的切换…16搜索服务模块…16搜索服务过程说明…16服务接口说明…17匹配算法…17Cache策略…18强大的过滤功能的实现…18文件类别过滤…18文件大小过滤…18文件最后修改时间过滤…18站点过滤…18精确匹配…18对"与"、"并"、*、操作以及结果中再搜索的支持…19WWW搜索界面…20CGI参数说明…20智能的换页机制…20使用结果页面模板…21多语言版本的支持…21漂亮、实用的结果输出页面…22为支持分布搜索的改进…22使用多服务器的可能性和必要性…22分布搜索的实现…22对分布搜索的加速…23支持多媒体文件的特别处理技术…23多媒体文件条目的文件名特殊性以及查询特殊性…23一种比较有效的处理技术…23在建库模块的改动…23在CGI模块的改动…24快捷方式系统…24使用快捷方式的原因…24快捷方式系统的关系图…24文件分类类别层次的显示…25快捷方式条目的显示…25注册新的软件…26过滤用户注册的快捷方式…26管理快捷方式系统…26天网ftp搜索与国内国际Ftp搜索引擎的比较…26国内国际ftp搜索引擎系统按原型分类说明:26功能比较:27数据量比较:28速度比较:28天网Ftp搜索引擎未来的发展…28结束语…29引言今天搜索引擎的核心是网络导航服务,搜索引擎是一个网络门户,他们提供新闻,在线图书馆,词典,以及其它网络资源,他们提供了不仅仅是网站搜索的服务,他们的涉及面越来越广,也越来越有用.
比如,Yahoo!
注重的是网站分类归总服务,而如AltaVista,Excite等则注重提供庞大的搜索数据库.
根据中国互联网络信息中心(CNNIC)有关中国Internet发展状况统计报告,搜索引擎是除电子邮件以外网民使用最多的服务.
面对浩如烟海的网络信息资源,网络搜索与导航已成为网络用户必不可少的工具.
与相对众多的WWW搜索引擎相比,功能强大的FTP搜索引擎并不常见,由此限制了人们对具有大量信息与资源的FTP站点的访问.
实现一个高速、海量、功能强大而又基于WEB的FTP搜索引擎将为网络用户提供极大方便.
为此,北京大学计算机系网络与分布式系统领域最新开发出了"天网"FTP搜索引擎,并已作为"天网"中、英文搜索引擎[1,2]的一个子系统在网上提供服务,获得了广大用户的一致好评.
本文将从"天网"FTP搜索引擎的系统结构与算法出发阐述一种千万级FTP搜索引擎的设计与实现的方案.
搜索引擎的历史与发展搜索引擎的起源1991年,XWAIS版本提供了一个有着友好界面的信息搜索系统,但这个系统要求很特殊的文件格式.
而在同一年还出现了另外一个信息搜索系统,这是我们所称之为的GOPHER.
Gopher是一种按"菜单"形式组织的分布式文档查询系统,最初在Minnesota大学发展起来(1991年),开始用于校园网,后来推广到Internet.
Gopher为用户查询信息提供一个多级的菜单界面,只需按照菜单指示的路径就能获取你想要的信息,使用非常方便.
Gopher由Gopher客户(GopherClient)程序和Gopher服务器(GopherServer)程序两部分组成.
在Internet上建立了数以千计的运行Gopher服务器程序的Gopher服务器.
它们是一些能为用户提供信息查询服务的计算机系统.
到1995年初的统计,约有6,000主机安装了GopherServer,遍及全世界100多个国家.
绝大多数Gopher服务器都是向所有Internet用户开放的.
Gopher系统的主要信息形式是正文文件.
信息文件可能驻留在不同的计算机上,通过目录结构把它们链接在一起.
一个Gopher服务器的所有信息文件组成一棵信息树.
由于这种链接是透明的,用户查询时可以在信息树之间自由穿越,不必考虑信息的物理位置.
Gopher客户程序是用户端的信息浏览程序,用于同GopherServer进行对话.
用户查询时,通过Client对Server发出查询请求;Server接收这种请求并把查询结果送回Client.
任何一台能够通过某种方式与Internet连接的计算机,都可以通过一定方法成为Gopherclient.
真正意义的搜索引擎最早的真正意义上的搜索引擎是Lycos,创建于1994年的春天,当时MichaelMauldin将JohnLeavitt的spider程序接入到其索引程序中.
Yahoo!
也是在当年成立的.
而NCSAMosaic出现在1993年,Netscape出现在1994年.
搜索引擎起源于传统的信息全文检索理论,即计算机程序通过扫描每一篇文章中的每一个词,建立以词为单位的倒排文件,检索程序根据检索词在每一篇文章中出现的频率和每一个检索词在一篇文章中出现的概率,对包含这些检索词的文章进行排序,最后输出排序的结果.
搜索引擎除了全文检索系统之外,还要有"蜘蛛"(SPIDER)系统,即能够从互联网上自动收集网页的数据搜集系统.
蜘蛛将搜集所得的网页内容交给索引和检索系统处理,就形成了我们常见互联网搜索引擎系统.
Ftp的搜索引擎I、基于文本的ftp搜索引擎:Archie.
Archie能在只知道文件名的前提下,为用户找到这个文件所在的FTP服务器的地址.
Archie实际上是一个大型的数据库,再加上与这个大型数据库相关联的一套检索方法.
该数据库中包括大量可通过FTP下载的文件资源的有关信息,包括这些资源的文件名、文件长度、存放该文件的计算机名及目录名等.
使用Archie服务器有三条途径,常用到的是:通过远程登录到Archie主机,用Archie作为登录名.
一旦登录成功,一个Archie程序将自动执行,这时一次输入一条命令,告诉Archie想查寻的内容,Archie将检索自己的数据库并显示检索的结果.
如果用户对自己想要的东西并不太清楚,Archie还提供"whatis"服务项目,该服务提供成千上万个程序、数据文件和文档的简短说明.
II、基于Web的Ftp搜索引擎.
WWW的出现改变了Archie在文件搜索方面的统治地位,在美观、方便的WWW页面上搜索ftp文件成为用户的一大需求.
在功能上,基于Web的ftp搜索引擎实现的功能与Archie基本一样,都是对用户提交的查询匹配串找到可以下载的ftp站点链接.
但基于Web的ftp搜索引擎也有很多特色的功能,比如天网ftp搜索引擎的文件分类功能等等.
基于Web的ftp搜索引擎也采用了很多WWW搜索引擎的策略,比如使用Spider自动收集数据,采用倒排索引,智能换页链接技术以及大型ftp搜索引擎必须采用的分布收集和服务技术.
目前国内国际ftp搜索引擎已有不少,但在系统底层上有区别的只有几种,其中较为有名的有北京大学天网搜索引擎的ftp子系统,华南木棉的ftp搜索系统,号称全球最大的ftp搜索引擎的philes.
com,以及lycos.
com使用的fastsearch.
com的fastftpsearch,小型网站常使用的NOSEYPARKER系统以及其他一些搜索引擎.
天网ftp搜索引擎的现状天网Ftp搜索产生的起源与发展历史.
在天网1.
0系统里,有一个简单的ftp搜索引擎,它只扫描几个教育网的ftp站点,算法上基本由unix命令组成,只能提供简单的字符匹配功能,而且界面很简单.
由于用户对ftp搜索的需求增加,我们在1999年秋开始了ftp搜索引擎的项目,并于2000年春交付了一个可以服务的百万级ftp搜索引擎,它搜索了30多个站点,提供150万的文件条目检索.
根据用户反馈和用户查询行为的分析,经过不断改进,在2000年秋ftp搜索引擎和天网的www搜索引擎同时升级并更换主页界面,提供了更为人性化的查询界面和结果界面,系统也更为稳定健壮.
2000年冬,天网ftp搜索引擎开始进行从百万级到千万级的改变.
直到2001年春,一个搜索了国内3000多个ftp站点,提供1300万文件条目索引,并有分类快捷方式系统的全新的天网ftp搜索引擎提供服务了.
天网ftp搜索引擎的现状提供的功能天网Ftp搜索引擎与其它ftp搜索引擎相比,最大的特点就在于它的功能强大.
尤其其中的文件类型过滤和快捷方式系统是所有ftp搜索引擎中独有的.
目前天网ftp所提供的各种功能包括:文件类型的分类目前文件类型分类分成图象、声音、视频、压缩、文档、程序、源代码、目录等.
文件分类的标准是按文件的扩展名.
由于天网Ftp搜索引擎有特有的文件分类功能,使得我们在搜索时精确度更高,比如要查电影"垂直极限",只需输入名字"垂直极限",选择"视频"类型,则各种文件类型的"垂直极限"的下载都找出来了.
如果没有类型过滤,则如果用户输入过于简单的话,可能查出的结果未必都是电影,如果用户输入包括了扩展名的话,则查询结果显然又少了很多,而且非计算机专业用户往往并不知道某个文件类的扩展名有些什么.
另外,在搜索的结果页面里,天网ftp搜索引擎使用了生动的图标区分各个类型的文件,使得文件所属类型一目了然.
文件分类已经成为了天网搜索引擎最强大又最有特色的功能.
时间过滤可以精确到年月日的文件最后修改时间过滤.
这个功能在寻找特定时间的文件时很有用.
大小过滤这个功能与文件类型过滤功能的集合,可以帮助寻找特定类型的文件.
比如同为".
dat"文件,有的是电影格式,有的是普通的数据文件.
但一般而言,大于40M的".
dat"文件应该是电影.
当我们加上这个限制的时候,也就可以找到扩展名为".
dat"的电影了.
精确匹配精确匹配对于查找短文件名的文件比较方便,系统缺省使用是子串匹配,因为子串匹配更符合普通人的思维.
站点限制在天网搜索的3000多个站点里,用户可以选择其中的某个站点,仅仅对其中的文件进行查找.
这个功能使得用户可以只搜对他(她)而言比较快的FTP站点,或他(她)比较喜欢的站点.
结果中查询功能很多WWW搜索引擎支持结果中查询的功能,但大部分Ftp搜索引擎并不支持结果中查询.
天网Ftp搜索引擎采用巧妙的算法实现了结果中查询的功能,使用户可以逐步缩小搜索范围,最终得到想要的结果.
支持常用的*,,与,并操作由于大部分用户的查询都不是十分精确的,*,,与,并这四个操作就显得十分重要.
与的操作符是空格,并的操作符是逗号.
这些操作的结合可以产生令人惊奇的结果,比如要查羽泉的《最美》,输入"羽泉最美",则用"羽泉"的查询结果和"最美"的查询结果作"与"操作,得到了用户想要的结果.
多语言版本天网Ftp搜索引擎在结果输出时采用模板技术,使得提供多语言、多界面的搜索结果页面成为可能.
目前天网Ftp搜索引擎支持简体中文和英文,并保留支持其它语言和其它模板的接口.
快捷方式系统快捷方式系统是天网Ftp搜索引擎独有的功能.
目前其它的Ftp搜索引擎仅仅提供了复杂的表单供用户提交查询,却没有考虑到广大搜索引擎用户大部分是普通网民而非计算机专业人士,使用上的简单化和傻瓜化是软件发展的必然.
因而天网Ftp搜索引擎建立了快捷方式系统,用户可以不输入任何字串,用鼠标就可以找到无数电影、音乐、程序、图片等等软件.
而且快捷方式系统包含了注册功能,用户可以注册自己关心的软件,以便其它用户可以很方便的得到搜索结果.
同时,我们对每个快捷方式的点击计数,在显示每一类快捷方式的时候排序,这样对于用户的非特定查询十分方便数据量站点数量在3000以上站点列表来源于手工获得和机器扫描,由于扫描了国内大部分网段,因为可以说天网ftp搜索引擎可以查到几乎国内所有的ftp站点.
2.
文件条目1300万左右据国外的统计,全球ftp站点文件数目约一亿两千万,也就是说天网ftp搜索引擎已经搜集到全球十分之一强的ftp网站.
对比已知的若干Ftp搜索引擎,我们可以说天网Ftp搜索引擎已经是国内最大的Ftp搜索引擎.
快捷方式约一千条这个数目将随着用户注册的增加而增加.
目前已经有528条电影快捷方式,295条音乐快捷方式,375条程序下载,59条开发资源快捷方式.
访问量日页面下载量在3万左右从2001年5月5日开始,我们记录了页面下载的总数,并定期计算每日页面下载量,下表(图1)为我们记录的页面下载日志统计:时间页面下载总数平均每日下载量2000.
05.
053053052000.
05.
0610117962000.
05.
101062524032000.
05.
111622556002000.
05.
132349436342000.
05.
153014733262000.
05.
173788338682000.
05.
194179719572000.
05.
204675749602000.
05.
225341033262000.
07.
2113856214192000.
07.
2214254839862000.
08.
1620228623892000.
08.
2622797425682000.
09.
0426306838992000.
09.
0527126181932000.
09.
0727789333162000.
09.
2437700358302000.
09.
2941070367402000.
10.
1751106755752000.
11.
0266001293092000.
11.
06702001104972000.
11.
20851550106822000.
11.
2388005495012000.
11.
24893388133342000.
11.
27925253106212000.
12.
111131402147242000.
12.
161213852164902000.
12.
181252818194832001.
01.
051502691146982001.
02.
14180067474492001.
03.
062108148153732001.
03.
092177719231902001.
03.
122265346292092001.
05.
133679936292092001.
05.
19385519029209图【1】天网ftp搜索引擎用户访问日志从上表可以看出,天网ftp搜索引擎从最初的每日访问量只有几百,上升到现在的每日3万,经历了约一年的时间.
在这一年里,天网ftp的用户随着天网的不断改进不断增加.
而且,其中访问量下降的阶段都是学校的暑假和寒假,由此得出访问天网Ftp搜索引擎的大部分用户是教育网用户.
日访问人数在1.
5万以上由每个用户平均查询一到两次算,估计天网Ftp搜索引擎现在每日的访问人数已经达到1.
5万以上.
而天网搜索引擎总的每日访问人数在4到5万之间,也就是说天网Ftp搜索引擎已经成为天网搜索引擎系统十分重要、不可缺少的部分,也是天网搜索引擎越来越受用户欢迎的一个因素.
海量ftp搜索引擎的系统结构设计系统的结构设计:四大模块和五个数据库参考WWW搜索引擎的一般系统结构,我们设计了如下的四个模块:搜集建库模块、搜索服务模块、CGI和WWW页面模块以及快捷方式系统.
其中使用了五个数据库包括:站点列表数据库、文件类型数据库、素材库、索引库、快捷方式数据库.
系统程序和数据的物理位置分配主要分七个部分:respath:源数据目录.
包括搜集建库的程序FtpCollect,站点列表库,文件类型库和素材库.
同时也存放搜集程序的日志.
basepath:主目录.
包括搜索服务器FtpServer,索引库.
其中索引库由三个子库组成,它们是:用于显示的Display库、用户过滤的Content库和用户匹配字串的Index库.
同时也存放建库程序的日志,搜索服务器的日志,页面下载的日志.
manage:管理程序目录.
包括快捷方式管理系统,站点列表获得程序FtpGetSite,IP站点列表和域名站点列表合并程序CheckSite、搜索服务器状态监控程序ServerKeeper等等.
其中快捷方式系统包括用户注册项过滤器ItemFilter和快捷方式条目管理ItemManage.
scripts:CGI目录.
包括提供服务用的CGI和快捷方式系统中的注册CGISubmit.
exe、条目显示CGITxtSearch.
exe,条目点击计数CGIFtpCount.
exe等等.
wwwpath:WWW页面目录.
包括主页面(中英文),搜索结果页面模板(中英文),复杂搜索页面模板(中英文),文件分类标志图片等等.
cachepath:搜索结果存放的缓冲目录.
SQL数据库系统.
目前使用的是MSSQLServer7.
0系统.
用于存放快捷方式系统里的数据.
系统结构关系如图2:传送请求发送请求回送结果发送请求回送结果客户方服务方图【2】海量ftp搜索引擎系统结构设计图数据库功能和结构说明文件类型库为了进行文件按扩展名分类,建立了文件类型数据库.
它对每类文件给于一个编号以及属于该类型的所有扩展名.
目前各分类的扩展名包括:1)图象:jpg,gif,bmp,jpeg,pcx,tif,tiff,wmf,psd,tga,pic,png,pcd,dib,rle,iff,lbm,ilbm,jpe,jif,dcx,ico2)声音:mp3,wav,cda,mid,au,mp1,m3u,mjf,as,voc,xm,s3m,stm,mod,dsm,far,ult,mtm,mp2,mpa,mpga,669,aac,mp4,vqf,pls,xpl,lrc,rmi,midi,snd,aif,aifc,wma,wax,aiff,rms3)视频:mpeg,mpg,avi,rm,swf,ram,rmm,ra,rmj,vob,asf,asx,wvx,wmv,wm,m1v,wmp,ivf,smi,mpv2,mp2v,smil,rp,mpv,ssm,rv,mpe,rf,rt4)压缩:zip,arj,gz,tar,tgz,cab,z,arc,b64,bhx,hqx,lzh,mim,taz,tz,uu,uue,xxe5)文档:txt,doc,htm,html,ppt,exl,mdb,asp,asa,php,js,rtf,wri6)程序:exe,com,bat,dll,class,out,ocx7)源代码:cpp,c,h,hpp,pas,bas,java,asm,perl,inc,cxx,tli,tlh,hxx,inl,def,odl,idl100)目录.
目录类型由文件条目属性决定.
0)其它.
所有不在上述范围内的文件归类到其它中.
文件类型库保存在FileType.
txt.
格式上采用文本格式,例如:图象photosjpg,gif,bmp,jpeg声音auidosmp3,wav,cda,mid这个库只在数据搜集程序中用到.
站点列表库站点列表库保存在下的sites.
txt里,每一行作为一个站点地址以文本格式保存.
站点列表来源于站点获得程序扫描得到的IP地址列表ipsites.
txt和手工产生的有域名的地址列表
amesites.
txt经过CheckSite.
exe程序合成产生.
站点列表库用于确定搜集程序搜集范围和建库程序的建库范围.
目前站点列表库大约有三千多个站点地址.
素材数据库素材数据库是由搜集程序产生的简单搜集结果.
搜集程序启动多个线程同时访问多个ftp站点,并行的将各个站点得到的文件条目经过简单的加工用存放在各个站点对应的素材库里.
比如ftp.
pku.
edu.
cn站点的文件条目信息保存在
esourceftp.
pku.
edu.
cn文件内.
每个文件条目按文件名、最后修改时间、文件大小、站内路径、文件类型以一行行字符串的形式保存在对应的素材库里.
例如:halfsize.
jpg文件名19700101最后修改时间13421文件大小(byte)/incoming/tools/htmledit/站内路径1文件类型(图象)由此可见,素材库是一个非结构化的数据库,这种结构能够适应长文件名情况,而在空间利用上也相对比较充分.
而如果采用固定大小的结构化数据库,则文件名和路径的长度就不得不作限制,最终导致不能正确访问下载地址或者可能浪费大量的存储空间.
索引数据库索引数据库是直接用于搜索的数据库,它关系到搜索服务的速度与效率.
它由用于显示的Display库、用于过滤的Content库和用于匹配字串的Index库组成.
我们采用双字母倒排表的方式组织索引表.
Index数据库中包含256*256个双字母索引文件,每两个字母对应一个索引.
其中Content库和Index库常驻内存,Display库只在输出结果时才被打开读取.
对每一个FTP站点的文件条目,将其文件信息如创建时间,大小,文件类型等非字符串定长数据以及一个指向显示文件中对应的文件名和路径字串起始位置的偏移指针(DisplayOffset)记录在Content库里,由数据在Content库的位置获得该文件的唯一编号(ID).
同时在文件名的每两个连续字母对应的双字母索引里生成以ID为高24位,该双字母组在文件名内的偏移为低8位的32位索引项.
Content库是结构化的库,保存在content.
dat里,它的条目结构为typedefstruct{charfiletype;//文件类型longfilesize;//文件大小long[4]site;//所在站点编号longcreatedtime;//创建时间,如1999年2月为:199902unsignedcharfilenamelen;//文件名长度longdisplayoffset;//对应的字串表示在DISPLAY库里的偏移}FileContent;//Index库包含256*256个双字母倒排表,保存在文件index.
dat里,它的结构为_int32indexoffset[256*256+1];//每个双字母表在库里的偏移和库结尾的偏移_int32index0_0[0号字母和0号字母组成的索引表_int32index0_1[0号字母和1号字母组成的索引表_int32index0_2[0号字母和2号字母组成的索引表…….
_int32index255_255[255号字母和255号字母组成的索引表每个双字母倒排表的长度可以由indexoffset的相邻两项计算得到.
倒排表由一系列32位结构组成,这个32位结构为typedefstruct{_int32ID:24;ID由该文件条目在Content库的编号决定_int32OffsetInFileName:8;//双字母在文件名里的偏移}IndexItemStruct;Display库为非结构化库,以适应无限长度文件名和路径名情况.
Display库保存在display.
dat里,它的每个条目的结构定义为halfsize.
jpg文件名19700101最后修改时间13421文件大小(byte)//ftp.
pku.
edu.
cn/incoming/tools/htmledit/Ftp路径文件类型(图象)快捷方式数据库快捷方式数据库由三个子库组成,用户注册查询项的临时库:TmpFileItem,快捷方式分类层次库:TypeList,快捷方式条目库:FileItem.
所有的快捷方式数据库都在MicrosoftSQLServer7.
0系统上实现.
临时库TmpFileItem的结构:IIDint//用于区分不用项的系统自动IDNamechar[64]用户注册查询项的名字,比如"rm电影"ToMatchchar[254]//用户注册查询项的内容,比如"word=*.
rm"TypeIDint//该注册项的类别号,比如"电影、MTV"类快捷方式条目库FileItem的结构:PIDint//该查询项的类别号,比如"电影、MTV"类Namechar[64]查询项的名字,比如"rm电影"ToMatchchar[254]查询项的内容,比如"word=*.
rm"DownloadCountint//用户点击该条目的次数IIDint//用于区分不用项的系统自动ID快捷方式分类层次库TypeList的结构:TypeIDint//类别的编号,如果整百则为主类,否则为子类Namechar[64]类别的名称例如:电影、MTV爱情动作MTV搜集建库模块搜集建库过程说明搜集建库运行的时机与频率是保证数据实时性的重要因素.
由于搜集时要访问众多的FTP站点、进行大量的网络数据传输,因而搜集应在网络速率比较快的时候进行,一般来说凌晨3、4点是最佳时机.
为了加快搜集的速度,我们采用多线程方式同时搜集多个站点的文件信息,并指定一个超时时间,以结束所有搜集,并转入建库程序.
搜集程序得到的数据保存在素材库里,以被建库程序使用.
建库程序将素材数据库转化为临时的索引数据库.
完成后通知服务器暂停搜索服务,用更改名称的方法将临时的索引数据库迅速切换为最终索引数据库,服务器重新读入索引数据库的索引库Index和内容库Content,开放对外搜索服务.
搜集建库过程如图3:图【3】搜集建库流程图站点获得策略Ftp搜索引擎与WWW搜索引擎最大的区别就在于Ftp站点内没有与WWW页面相对应的超链接,因而Ftp搜索引擎的站点获得策略就不能模仿搜索引擎业非常时兴的超链分析技术.
在北大天网Ftp搜索引擎里,我们采用了IP扫描技术和手工添加技术的中和.
一方面,我们用GetFtpSite.
exe扫描全国网段,比如北大的162.
105下的所有可能IP地址,把每个提供了ftp服务的站点IP保存到ipsites.
txt里.
另一方面,我们依靠搜索引擎用户提供给我们的有域名的Ftp站点名称,以及管理员自己找到的常用的ftp站点地址,存放到
amesites.
txt里.
然后调用CheckSite.
exe合并ipsites.
txt和
amesites.
txt,消除其中的IP地址重复的项,并代之于域名.
同时把没有扫描到的已知ftp站点添加进去,最后产生sites.
txt文件,也就是搜集建库使用的ftp站点列表.
为了使得IP扫描到更稳定开放的机器,我们一般在晚上启动IP扫描程序GetFtpSite.
exe.
并发搜集策略由于ftp搜索引擎搜集的站点数目极其巨大,目前已经有大约三千多个ftp站点在搜集范围内,如果采用单线程显然是不现实也没有必要的.
我们的ftp搜索引擎采用有限的多线程搜集模式,一般同时启动约三百个线程,并精确计算当前运行的线程总数,每十分钟检测一次启动线程数是否达到三百个,如果没有,则再启动新的线程搜集新的站点.
线程的数目一方面受限于系统的最大线程能力,另一方面则受限于所有线程打开资源的总数.
由于在天网ftp搜索引擎中,每个搜集线程至少打开一个文件,因为线程总数受限于系统可以打开的文件总数.
因而我们经过测试和比较,得到同时打开三百个线程是最佳的.
每个线程打开的这个文件就是素材库里一个站点对应的素材文件,比如ftp.
cs.
pku.
edu.
cn它所对应的素材文件就是
esourceftp.
cs.
pku.
edu.
cn,由于每个线程所写的资源各自独立,因而并不会有共享冲突.
分布搜集策略在最新的Ftp搜索引擎里,为了应付可能发生的系统内存或者硬盘资源不足的情况,我们设计了多台计算机分布搜集分布服务的策略.
具体而言就是把一部分ftp站点列表给某台计算机,使它对这些ftp站点搜集并建库.
当用户提交搜索请求时,CGI程序把请求发送到各个独立的搜索服务器,并把合并后的结果返回用户.
对用户而言,他(她)并不会知道后台使用了分布策略,但搜索速度和数据量都大为增强了.
多次尝试和断点续搜考虑到国内网络的现状,网络的不稳定性成为影响搜集完整性的重要因素.
比方很多ftp站点对访问人数作了最大限制,因而一个ftp站点当时不能访问并不是说它是不可访问的,我们采用了三次尝试,每次尝试失败后休眠两分钟继续尝试,如果三次之后仍然无法访问,则说明该站点的确访问不了.
另一方面,在搜索引擎得到ftp文件条目的过程中,也可能发生各种网络故障以致忽然中断,为了解决这个问题,我们采用了断点续搜的功能.
当搜集过程中发生异常(Exception)以致搜集中断时,线程休眠两分钟,利用保存的未搜集目录表从中断发生的目录继续搜索,而且这个搜集过程的启动也是三次尝试,但搜集的结果是在原来搜集结果中继续增加.
这样,我们就可以得到基本上完整的该ftp站点的文件条目列表.
线性的建库过程建库过程是线性的,这是因为要给每一个文件条目一个系统唯一的ID,这个ID就是该文件条目在索引库的Content子库里的记录号.
为了在建库的过程中保存无法预知大小的双字母索引,我们采用临时文件策略,在index下安双字母建立对应的独立文件,比如双字母则对应文件为index4654.
这样只要在文件条目的文件名里有字母对则在index4654里增加一个大小为32位的IndexItemStruct结构.
但是我们打开所有256*256个文件以便随时写入新的索引是不可能的,因为可以打开的文件数有限,如果每写一个索引打开一次文件则建库过程将极为缓慢.
因此我们采用了缓冲技术,为每个双字母索引建立了一个较小的Cache,只有当Cache满的时候才打开并写入对应的双字母索引文件.
在所有的ftp站点的素材库都转化为临时的索引库后,将index下的所有文件合并到临时索引库的index库里,即 mpindex.
dat文件.
数据库的切换当临时的索引库建完之后,服务器必须停止服务,并释放旧的数据库的锁定,删除旧库,把临时数据库切换成实际使用的数据库,再启动服务.
同时删除所有的Cache,因为它们已经无效了.
目前在1300万文件条目的数据量下,切换整个数据库所需的时间大约几分钟,基本不影响日常的搜索服务.
搜索服务模块搜索服务过程说明服务器是系统的核心,必须保证稳定性和高效性.
实现高效性的关键在于使用线程,即一个用户请求使用一个线程处理.
由于用户的搜索请求具有随机性和并发性,因而线程互斥、死锁预防、资源的管理等是服务器必须解决的重要问题.
另外,对于由于某种原因(如内存不足、I/O错误等)不能正常完成搜索任务的线程,必须正确而完整的释放它申请的资源(如申请的内存、打开的文件、打开的Socket以及线程本身),并向用户显示不能完成任务的原因.
安全性也是服务器要考虑的一个方面.
服务器采用了TCP/IP作为与CGI通讯的协议,因而可能存在其它程序乃至网络黑客的非法连接.
我们可以采用一种简单的身份验证机制保证安全,即CGI与服务器连接时先输入一个约定口令,若口令错误,则服务器直接关闭这个非法连接,从而确保了服务器的安全性.
服务器会接收到来自CGI的搜索请求或搜集建库程序的更新数据库请求,接到更新数据库请求后,服务器暂停接收CGI的搜索请求,读入新的数据库,然后继续对外服务.
接到搜索请求时,由CGI发送来的请求信息确定要匹配的串和过滤信息.
由搜索串检查Cache是否命中(Cache是以搜索串为文件名,以匹配结果的所有ID为内容的文件),若命中,读入Cache,进行信息过滤,输出结果.
否则,重新在数据库里查找,将结果过滤输出,然后将没过滤的结果ID串写入以搜索串为文件名的Cache文件中.
输出结果给CGI时,由ID找到对应的文件信息记录,并由文件信息记录找到文件名与路径,最后以字符串格式发给CGI.
服务器响应总流程如图4:数据更新暂停服务读入新数据库重启服务搜索请求Cache检测过滤输出图【4】服务器响应流程服务接口说明服务接口是一个Socket接口,CGI程序或者搜集建库程序用它与服务器通讯.
当搜集建库程序要求服务器切换数据库时,它只需在对应的Socket端口发一个字符格式的"****FtpStop***"命令即可.
当用户查询时,CGI在这个端口写一个SearchStruct结构,以给出查询参数.
当然,在给这个端口写数据前有一个用户校验过程,以保证服务器的安全性.
SearchStruct结构定义如下:typedefstruct{chartomatch[32]匹配串longsites[4]受限站点的编号boolCaseSensitive;大小写敏感标志boolExactSearch;精确匹配标志charsearchtype;//搜索类型:0为简单搜索,1为复杂匹配(有附加条件)charfiletype;受限文件类型longbegintime,endtime;受限时间范围,如1999年2月为:19990200longbeginsize,endsize;受限大小范围longshowfirst,showmax,resultnum;//显示起始点,最大显示数,结果总数}SearchStruct;//匹配算法查找是基于数据库里双子母倒排表的操作,通过提取两条索引中高24位(ID值)相等、低8位(字母在文件名中的偏移)有确定差值的索引项获得结果.
具体而言,对连续的三字母串(如abc),取后一双字母索引(bc)与前一双字母索引(ab)中ID相等的项,若后一索引(bc)中的偏移大1,则为所求结果的一项.
而对于abcd、abcd等,则取偏移大于2、大于3即为所求结果.
对于ab*cd,则要求在后一索引(cd)中的偏移大于它在前一索引(ab)中的偏移.
Cache策略为了加快速度和实现结果中过滤的功能,我们把搜索结果暂存在Cache,以便下次使用.
Cache保存的是字符串匹配的结果,而不是过滤后的结果.
用文件形式保存结果索引做为Cache,以匹配串的16进制码作为文件名存放在目录下.
Cache文件的存在周期为2个小时,每隔两个小时服务器自动删除所有最后访问时间超过两个小时的Cache文件.
另外,在CGI参数里我们有一个结果总数,这个结果总数有SearchStruct结构传递到服务器.
当服务器发现ResultNum不为-1时,就假设这个ResultNum是已知的结果总数.
这样进行匹配结果的属性过滤时就没有必要从头过滤到结尾,只需过滤到需要显示的范围(showfirst…showfirst+showmax)就可以了.
这是一个虚的Cache策略.
应用Cache的效果是十分显著的.
例如查询"c*.
jpg"时,如果Cache没有命中是1734毫秒查出45417个结果,Cache命中时是31毫秒,当CGI参数里把结果总数加进去时是16毫秒.
由此可见Cache是多么重要.
强大的过滤功能的实现文件类别过滤文件类别过滤功能是基于文件分类.
在搜集程序建立素材库的时候,就对每个文件条目的文件类型进行归类,目前文件类型分类分成图象、声音、视频、压缩、文档、程序、源代码、目录和其它.
在建库的时候,文件类型信息写入每个文件条目的Content库的结构里.
当字符串匹配完成进行文件类别过滤的时候,只要SearchStruct.
Searchtype与FileContent.
filetype相等或者SearchStruct.
Searchtype为0即所有类型则过滤成功,这个条目就作为结果的一项输出给用户.
文件大小过滤缺省的大小过滤是0到1.
G的范围.
用户可以用复杂查询表单指定起始大小和终止大小范围,利用Content库里的文件大小属性,过滤匹配串的结果得到最终结果.
文件最后修改时间过滤缺省的时间范围是1980-2050年之间,时间范围的指定可以精确到特定的日期.
实现上使用Content库的最后修改时间过滤实现.
站点过滤站点限制是我们的ftp搜索引擎比较有特色的功能,实现上比较简单,关键是给每个ftp站点一个编号.
在最后的结果过滤时,把站点范围合适的结果输出即可.
精确匹配精确匹配的实现的判断比较复杂,当匹配串里没有*且没有使用"与"、"并"操作或者结果中查询时,精确匹配才是有可能的.
这时将匹配串的长度与Content库里的filenamelen文件名长度作比较,如果相同则精确匹配通过.
对"与"、"并"、*、操作以及结果中再搜索的支持在ftp搜索引擎里提供"与"、"并"、*、操作以及结果中再搜索相对其他ftp搜索引擎里是比较有特色的,因为很多ftp搜索引擎并不支持这些十分常用的传统上只有WWW搜索引擎才有的功能.
"与"的操作符是空格,"并"的操作符是逗号,结果再搜索的分割符是char(3),由CGI程序产生这个分割符.
这样,无论怎么样的搜索度都可以把它的字符串匹配项放再一个字符串里.
比如要查*.
rm或者*.
mpg结果里的"americanpie",则这个查询串的最终形式是:"americanpie"+char(3)+"*.
rm,*.
mpg".
在系统实现是,对这个字串的解释是顺序的,也就是得到"americanpie"这个当前查询项,然后发现需要在结果"*.
rm,*.
mpg"里查询,则在Cache里找到"*.
rm,*.
mpg"的查询结果,因为这个结果是必然存在的,否则就不能算是结果中查询了.
将"americanpie"的查询结果和"*.
rm,*.
mpg"的查询结果合并,就得到在"*.
rm,*.
mpg"里查询"americanpie"的结果了.
而在实现"americanpie"的查询时,则用*代替空格,以实现与的操作.
而实际上用户也正需要这个操作.
下面是实现Cache命中和结果中查询的逻辑流程图(图5):图【5】Cache逻辑和结果中查询逻辑WWW搜索界面网页是FTP搜索引擎的用户界面.
美观大方、使用方便以及兼容不同操作系统下不同浏览器是网页设计的标准.
用户的输入页面有两种:简单查询与复杂查询页面.
简单查询只有一个输入框用以输入要搜索的字串,其它限制信息由CGI缺省给出.
简单查询可以和WWW查询集成,由用户选定使用WWW搜索器还是FTP搜索器查找.
复杂查询由一个复杂表单供用户选定各种过滤,如时间,大小,站点,类型过滤等.
另外,最新的天网ftp搜索引擎增加了快捷方式系统,使得WWW搜索界面更为方便,快捷方式系统另外独立描述.
CGI程序从网页表单的提交或直接由URL得到搜索要求,进行参数检查.
然后将搜索请求发往服务器,服务器将过滤后的结果信息返回,CGI程序按此生成网页.
CGI参数说明CGI参数分成两类,一类是搜索用的,一类是显示页面用的.
用于搜索的参数有:word匹配串,缺省为".
exe"ResultNum已知的结果总数,缺省为-1,即未知结果数SearchType确定是否需要过滤属性,缺省为0,即不过滤Fromyear起始年号,缺省为1970Frommonth起始月份,缺省为1Fromdate起始日期,缺省为1Toyear终止日期,缺省为2050Tomonth终止月份,缺省为12Todate终止日期,缺省为31FromSize起始大小,缺省为0ToSize终止大小,缺省为0x7fffffff,接近4GFileType受限的文件类型编号,缺省为0,即所有文件类型Inputstr表单里的已知查询字串,如果它不空即是结果中查询ExactSearch精确匹配选项,缺省为0,即不是精确匹配Site受限站点编号,缺省为0,即所有站点用于显示的参数MaxHits每页显示的结果数目,缺省为40BeginWith当前页显示的起始结果编号,缺省为0Single结果页面的显示样式:表单或者条目,缺省为条目样式Cdtype结果页面的语言版本:gb:简体中文,big5:繁体中文,en:英文,缺省为简体中文智能的换页机制由于大部分情况下搜索结果在一页内显示不了,因而要采用换页机制.
即CGI程序向服务器提供起始显示项号和最大显示项数,由服务器过滤,将可显示的结果信息返回给CGI程序.
CGI程序由服务器给出的结果总数和起始显示项号生成换页链接.
在北大"天网"FTP搜索引擎里,我们采用了一种智能的换页方案:将当前的起始显示项号对应的链接放在链接表的中间,以最大显示项数为间距生成有限个向后和向前的链接.
这样用户可以保持鼠标不动的情况下,以相同的间距向前或向后翻页.
如图6所示为最大显示数为20时的一种情况:02050709011013015017019021023025027029031050709011013015017019021023025027029031033035090110130150170190210230250270290310330350370390鼠标不动,每次跳过40个图【6】一种智能的换页方案使用结果页面模板为了使ftp搜索得界面更为灵活,将算法和界面分离的模板技术是十分方便有用的.
模板技术的使用,使得多语言版本实现成为可能,也为以后可能的应用服务提供基础.
目前的模板里采用Html语法里的特定标注作为模板插入点.
这些特定标注是:结果中再搜索表单匹配串搜索消耗的时间搜索的结果总数起始显示的结果编号终止显示的结果编号所有结果的翻页索引结果显示区域在所有标注里,只有是在一个页面里只能使用一次的,其他标注可以多次使用.
而且各个标注的顺序是不定的,但要求标注必须占用一行的起始位置.
当CGI要显示结果的时候,它逐行读入模板文件,如果该行以特定标注开头,则用CGI里的特定显示字串代替它,否则直接输出.
多语言版本的支持在结果页面使用模板技术后,ftp搜索引擎就可以提供多语言的版本了.
一方面,静态页面比如查询输入页面可以用手工的方法制作各个语言版本的页面,而结果页面,制作特定语言的模板即可.
但CGI也要做些改动,因为结果中再搜索表单和翻页索引里有语言相关的字符.
目前天网ftp搜索引擎提供简体中文和英文两个语言版本,并在CGI里已经实现里繁体中文的支持,但没有提供给用户使用.
漂亮、实用的结果输出页面如图7:图【7】天网ftp搜索结果页面示意图为支持分布搜索的改进使用多服务器的可能性和必要性当搜索引擎搜集的站点数目越来越大,数据量也同步很大时,单部PC机完成所有的搜集建库工作就显得比较艰辛.
一方面内存成为瓶颈,因为按目前的情况,一千万的文件条目需要700M的内存,由于搜索引擎的搜集范围的扩大,所需内存马上就会超过数千兆,这是普通服务器所难于承受的.
另一方面,站点数目的增多使得重新刷新一次数据库所需的时间增大,如果都放在一台服务器上周期太长,不能更快的体现ftp站点的变化.
所以使用多个服务器进行分布搜集数据和分布搜索是未来发展得方向.
分布搜索的实现最新的天网ftp搜索引擎支持了分布搜集和分布搜索,这为系统的未来扩展垫下基础.
在ftp搜索引擎原有结构上实现多服务器的分布数据搜集和分布搜索并不难,因为在系统的Server/Client结构为系统的分布提供基础.
将多个独立的Server分别搜集不同网段的ftp站点并为这些站点数据的搜索提供搜索服务,令Client分别连接到各个服务器,将各个服务器得搜索结果合并后输出给用户.
这样,我们并没有改动服务器端的任何代码,在服务器的所作改动就是限制其站点列表数据库,使得各个服务器的站点列表数据库没有交集.
而在CGI客户端,通过系统配置可以知道各个服务器的地址,CGI将搜索请求发给各个服务器,计算总得结果数,并确定可以显示得结果范围,最后输出给用户.
对分布搜索的加速在未知搜索结果总数的时候,CGI必须把每个搜索请求发给各个服务器,实际上当前显示页面后面的结果是不需要查询的,查询的目标也仅仅是为了得到结果总数.
因而,如果在第一次查询得到结果总数后,我们把结果总数放在后续翻页的CGI参数里,这样,后续的翻页动作时已知了结果总数,我们按续请求部分服务器,在当前显示页面的结果得到后就不必再请求其他服务器,这样就加速了翻页的过程.
支持多媒体文件的特别处理技术多媒体文件条目的文件名特殊性以及查询特殊性多媒体文件,比如视频和音频文件,都有一个典型特征就是大量文件的文件名并不是确定该文件内容的字串.
比如视频文件的文件名可能是a.
rmb.
rm而不是具体电影名.
rm,或者文件名使用的是英文而不是翻译过来的中文,这样对于用户而言,就很难找到他(她)所需要的文件.
对于音乐,一方面可能文件以歌名为文件名而不是以歌手的名字为文件名,但对于用户查询而言可能两个都是需要的,另一方面与电影文件名类似,就是cd盘改录的音频可能使用track0.
mp3track1.
mp3等等名字,而这个名字根本无法确定音乐的内容.
一种比较有效的处理技术解决这个问题的办法是利用ftp站点目录的分类能力,一般而言,目录名说明了这个目录的内容,如果我们把多媒体文件的目录名与文件名一起去匹配查询串,则上述问题就可以轻易解决.
在我们设计的搜索引擎里,我们将具有音频和视频类型的文件条目的文件名与其上一层目录名合并.
比如电影"罗马假日/1.
rm","罗马假日/2.
rm".
这样,当用户查询"罗马假日"的时候就能得到其想要的下载地址,并且,由于使用了类型过滤,用户可以精确的只找到"罗马假日"的电影格式文件,而不是它里面的主题曲或者介绍文本.
在建库模块的改动由于采用了上述技术,必须对ftp搜索引擎里的建库模块和CGI做些改动.
在建库模块,必须把多媒体文件的文件名和其上一层目录合并一起建索引,否则查询时就无法得到正确结果.
同时,在索引库的Display库里,直接用上一层目录名/文件名的格式代替文件名保存.
在CGI模块的改动在CGI中,由于搜索时已经采用了对多媒体文件的文件名和上层目录名合并技术,因而在结果显示的时候不能只显示文件名.
比如用户查询"罗马假日"却只给出"1.
rm"、"2.
rm"作为结果,显然会使得用户不知所以,以为系统出错,因而在结果显示的时候,也得把上一层目录名/文件名格式显示给用户,同时也要保证下载地址的正确性.
快捷方式系统使用快捷方式的原因经过对用户查询的日志分析,可以得到的结论是用户经常不知道要在搜索引擎找什么东西.
搜索引擎如果只提供一个输入框和一大堆复杂的表单对于普通用户而言可能会不知所措.
由于ftp搜索引擎具有一个特性就是用户搜索的关键词范围比较有限,如果把比较流行的软件的查询做成快捷方式,用户一点击就可以得到该软件的查询结果,则用户到搜索引擎要做的就不再是指明自己要什么,而是搜索引擎可以告诉他(她)可以要什么.
快捷方式的使用可以极大的鼓励普通用户使用搜索引擎,但快捷方式具有一个缺陷就是可能该快捷方式没有任何查询结果,而这对于用户来说是很让人失望的.
一个策略就是,在服务器切换了新的数据库后,对所以的快捷方式进行检查,如果没有查询结果则删除.
但这仍然不是好办法,可能一个很热门的查询被删除掉了,但在下一次建库后可能该快捷方式又有查询结果了.
目前天网ftp对这种情况的没有处理,由管理员定期删除不热门又经常查不出结果的快捷方式.
当搜索引擎具有了文件分类功能和对多媒体文件名的特殊处理之后,建立一个两层分类的快捷方式系统就可行了.
这是因为在快捷方式里,查询结果必须比较精确的在一个文件类型范围内,比如用户想查应用程序是不能给他(她)一大堆该应用程序的源代码的.
同时,经过对多媒体文件名的特殊处理之后,对于多媒体文件名的电影名,歌星名的查询与文件类型过滤的结合使得查询多媒体文件十分精确.
快捷方式系统的关系图我们的ftp搜索引擎的快捷方式系统由七个部分组成:分类类别层次显示CGI,快捷方式条目显示CGI,快捷方式注册CGI,快捷方式点击计数CGI,注册条目过滤程序,快捷方式条目管理程序以及SQL数据库系统.
用户访问它们的关系如图8:图【8】快捷方式逻辑图文件分类类别层次的显示通过查询数据库,得到快捷方式的两层分类.
CGI用限制显示行宽的格式显示顶层快捷方式分类及它的子类.
每个分类链接到文件分类条目显示CGI上.
比如:·程序下载系统办公、网络聊天、媒体图象、驱动压缩、专业软件、桌面布景、电脑游戏、病毒与安全、为了使得分类层次显示页面的灵活性,我们采用了页面模板技术,CGI读取模板index_src.
htm,将其中的特定标注替换为分类层次.
另一方面,考虑分类层次是基本上不会改变的,直接把CGI的显示页面保存成静态html文件,作为ftp搜索引擎的首页.
快捷方式条目的显示快捷方式条目的显示使用了ftp搜索引擎结果页面模板,页面上结果中查询的表单变成了注册新软件的表单,查询结果区域显示该分类的快捷方式条目,每一行显示四个快捷方式和它们的点击计数,每页显示80个快捷方式条目.
快捷方式条目的显示如图10:图【10】快捷方式条目显示图注册新的软件在快捷方式条目显示页面上方有一个注册新软件的表单,该表单显示该页面的快捷方式分类类别,并可以输入软件名立即注册.
快捷方式注册程序注册完后马上转向到ftp搜索引擎的搜索CGI显示查询的结果.
另外,我们对注册新软件的查询项做了些特别的处理.
如果注册的类别是快捷方式电影分类下的子类,则查询时增加文件类型为视频的过滤,而音乐的对应音频文件类型,图片的对应图象文件类型,开发文档的对应文档文件类型.
这样就使得在特定分类的快捷方式里只能找到该类别的文件,比如在电影类别的快捷方式下只能看到视频类型的文件查询结果.
过滤用户注册的快捷方式由于用户的注册有很大的随机性,不可能把用户注册的软件的快捷方式直接显示给其他用户使用.
因而所有注册的快捷方式条目都必须经过手工的过滤或者修改.
过滤修改的标准是快捷方式的分类是否正确,查询是否足够精确,以及是否已经有类似的快捷方式,英文条目的首字母是否大写等等.
管理快捷方式系统由于有部分快捷方式查询结果可能在下一次建库后就再也查不到结果,因而必须对快捷方式进行管理,同时也对一些快捷方式分类错误进行改动.
定期的管理使得快捷方式更为精干,同时也消除了错误.
与国内国际Ftp搜索引擎的比较国内国际ftp搜索引擎系统按原型分类说明:philes.
comlinux.
org的产品,自称是全球最大的ftp搜索引擎网址:http://www.
philes.
com/天网ftp搜索北京大学计算机系网络教研室制作网址:http://bingle.
pku.
edu.
cn/FtpSearchv3.
4作者TorEgge网址:http://archie.
is.
co.
za/ftpsearch/fastftpsearchfastsearch.
com的产品使用这个系统的网站有:http://ftpsearch.
lycos.
com同时lycos.
com也作为应用服务提供给其他网站NoseyParkerJiriA.
Randus使用这个系统的网站有:http://parker.
vslib.
cz/parker.
htmlhttp://student.
cs.
tsinghua.
edu.
cn清华酒井http://search.
igd.
edu.
cn/全军基因诊断技术研究所FTP检索引擎LapLinkftpLapLink.
com的产品网址:http://ftpsearch.
laplink.
comALLA(AllaLooksLikeArchie)网址:http://alla.
ms.
mff.
cuni.
cz/8)filesearching.
comChertovyKulichkiInc产品网址:http://www.
filesearching.
com/功能比较:站点*,结果中查询复杂表单搜索多页换页基于archie天网ftp搜索是是是是否FtpSearchv3.
4是否是否是华南木棉ftp检索是否是是否NoseyParker是否否下页换页否www.
philes.
com是否否是否ftpsearch.
laplink.
com是否否否否ftpsearch.
lycos.
com是否是是是www.
filesearching.
com是否是是否alla.
ms.
mff.
cuni.
cz是否是下页换页否从上表可以看出,在功能上天网ftp搜索引擎具有强大的功能,比如其结果中查询等功能其他搜索引擎都没有实现.
数据量比较:站点文件条目总数站点总数*.
txt结果数linux的结果数天网ftp搜索13,000,0003200269,37816,936FtpSearchv3.
4没有统计没有统计15,0004,288华南木棉ftp检索近百万没有统计41,1063,444NoseyParker没有统计2014,1466,278www.
philes.
com168,845,992没有统计限制24,000限制24,000Ftpsearch.
laplink.
com37,813,0402683不支持*开头1,612Ftpsearch.
lycos.
com没有统计没有统计不支持*开头1,250www.
filesearching.
com没有统计没有统计限制在1000内限制在1,000内alla.
ms.
mff.
cuni.
cz没有统计没有统计127,00022,259从上表可以看出,天网ftp搜索引擎的数据量已经在全球排前几名,同时也是国内最大的ftp搜索引擎.
速度比较:站点*.
txtAb*cdlinux天网ftp搜索94ms269,378结果47ms489结果32ms16,936结果FtpSearchv3.
4300s15,000结果149ms84结果109s4,388结果华南木棉ftp检索没有费时统计没有费时统计没有费时统计NoseyParker没有费时统计没有费时统计没有费时统计www.
philes.
com674ms24,000结果650ms229结果772ms24,000结果ftpsearch.
laplink.
com没有费时统计没有费时统计没有费时统计ftpsearch.
lycos.
com没有费时统计没有费时统计没有费时统计www.
filesearching.
com没有费时统计没有费时统计没有费时统计alla.
ms.
mff.
cuni.
cz没有费时统计没有费时统计没有费时统计从上表可以看出,天网ftp搜索引擎是所有有费时统计的ftp搜索引擎里最快的一个,即使在处理目前的千万级数据量,天网仍然能够在几十毫秒内完成任务,远远超过其他的搜索引擎.
天网Ftp搜索引擎未来的发展天网ftp搜索引擎从开始创作到现在的一个千万级大型系统,经历了两年的时间.
这两年里,天网ftp搜索引擎不断发展进步,努力朝最好、最快、最大的ftp搜索引擎目标进发.
展望未来,天网ftp搜索引擎可以在站点列表获得策略上进行改进以便减少死链的存在并增强搜索结果的有效性.
另外,增加结果输出的排序(按最后修改时间或者大小)的功能也十分必要.
同时,要把天网ftp搜索引擎从千万级上升到亿级还有一个艰辛的过程.
我想我们会继续努力,天网搜索引擎将更受人们的欢迎.
结束语最后感谢北京大学计算机科学技术系网络与分布处理领域的老师和同学们在北大天网ftp搜索引擎的创立和发展中对我们的支持与帮助,特别感谢李晓明老师和王建勇老师对我们的悉心指导.
同时,也感谢对天网ftp搜索引擎的广大用户,用户的支持是天网ftp搜索引擎得以日益发展的关键.
主要作者简介:陈华1978年出生,籍贯广东,正在北京大学计算机科学技术系攻读学士学位参与项目开发的其他人员:罗昶、段辉、薛明参考文献:陈华、罗昶、段晖、薛明、王建勇.
基于Web的百万级FTP搜索引擎的设计与实现.
已发表在《计算机应用》1000年第9期.
雷鸣,刘建国,王建勇,陈葆珏.
一种基于词典的搜索引擎系统动态更新模型.
已被《计算机研究与发展》录用.
- 海量的基于Web的FTP搜索引擎系统的设计与实现相关文档
- 甘肃省政府采购招标文件招标编号:ZFCG-XH-2015-169
- 《农业知识综合三》复习大纲
- 计算机网络公共实验(一)(001731)课程介绍
- ,"配置清单",,,,
- 门禁ftp教程
- 安安ftp教程
Raksmart VPS主机如何设置取消自动续费
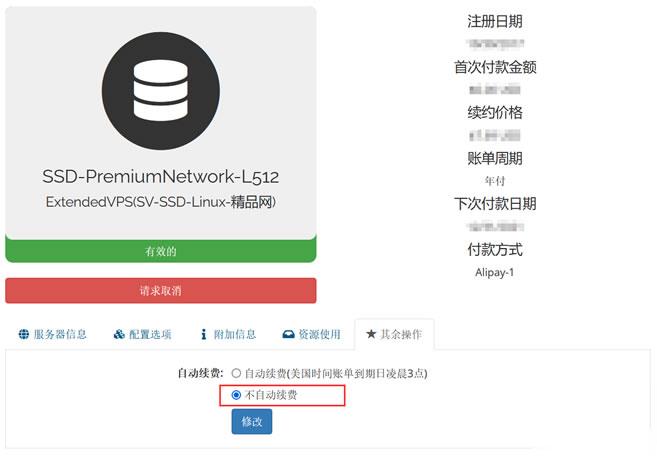
今天有看到Raksmart账户中有一台VPS主机即将到期,这台机器之前是用来测试评测使用的。这里有不打算续费,这不面对万一导致被自动续费忘记,所以我还是取消自动续费设置。如果我们也有类似的问题,这里就演示截图设置Raksmart取消自动续费。这里我们可以看到上图,在对应VPS主机的【其余操作】中可以看到默认已经是不自动续费,所以我们也不要担心被自动续费的。当然,如果有被自动续费,我们确实不想续费的...
美国cera机房 2核4G 19.9元/月 宿主机 E5 2696v2x2 512G
美国特价云服务器 2核4G 19.9元杭州王小玉网络科技有限公司成立于2020是拥有IDC ISP资质的正规公司,这次推荐的美国云服务器也是商家主打产品,有点在于稳定 速度 数据安全。企业级数据安全保障,支持异地灾备,数据安全系数达到了100%安全级别,是国内唯一一家美国云服务器拥有这个安全级别的商家。E5 2696v2x2 2核 4G内存 20G系统盘 10G数据盘 20M带宽 100G流量 1...
DMIT:新推出美国cn2 gia线路高性能 AMD EPYC/不限流量VPS(Premium Unmetered)$179.99/月起
DMIT,最近动作频繁,前几天刚刚上架了日本lite版VPS,正在酝酿上线日本高级网络VPS,又差不多在同一时间推出了美国cn2 gia线路不限流量的美国云服务器,不过价格太过昂贵。丐版只有30M带宽,月付179.99 美元 !!目前美国云服务器已经有个4个套餐,分别是,Premium(cn2 gia线路)、Lite(普通直连)、Premium Secure(带高防的cn2 gia线路),Prem...

-
域名查询怎样查看域名是在哪个平台备案的中国互联网域名注册中国互联网域名注册怎么操作info域名注册百度还收录新注册的info域名吗?asp主机空间asp空间是什么域名注册服务万网域名注册服务怎么样?代理主机如何将我工作的电脑设置为代理主机 让我回家以后可以用家里的电脑连接店里的主机访问网络查询ip如何查IP网址个人虚拟主机个人商城要选多大的虚拟主机?100m网站空间50M的网页内容买100M的网站空间够用了没?国外网站空间国内空间 美国空间 香港空间相比较,哪个好?